
Espresso #9: Real-time analytics' big moment and managing fewer data layers

Hello data friends,
This month, we’re diving into how (and why) streaming is becoming more accessible in the data space and the fate of the data platform’s raw/bronze layer. So, without further ado, let’s talk data engineering while the espresso (or cappuccino if you’re feeling adventurous) is still hot.
Will 2025 be the year real-time analytics finally goes mainstream?
Since the Hadoop era and the early days of Big Data, one prediction kept coming back year after year: “Next year will be the year of streaming.” There was a constant expectation that eventually, most (all?) data pipelines would evolve to real-time patterns instead of batch processing. Yet, despite the hype, real-time analytics has largely remained limited to tech giants and niche industries with highly specialized streaming needs.
By this time, the general consensus in the data space is “you don’t need streaming” / “batch is (mostly) always enough”. However, I believe 2025 might finally be the year streaming makes sense for common data use cases. This year, two key factors might allow real-time analytics to break out of its niche and finally hit the mainstream.
Streaming’s unfulfilled promise
Streaming is exciting. The ability to process and analyze data at scale in real time, unlocking insights and enabling immediate action, has been a core promise of data platforms ever since the Hadoop era. But then the realities of its technical challenges, coupled with the lack of concrete and valuable-enough use cases, often lead data teams to the catch-all “But do we really need it?” counter-argument.
Technologies like Apache Storm and Apache Flink solved many of the technical hurdles, but the fundamental constraints remained: Building and maintaining streaming pipelines required complex infrastructure, specialized skill sets, and significant financial investment. As streaming for pure data movement gained traction in the software engineering world, with patterns like event-based architectures and a meteoric rise for Apache Kafka, the data world remained stuck with batch processing, and architectures like the one below became the standard:
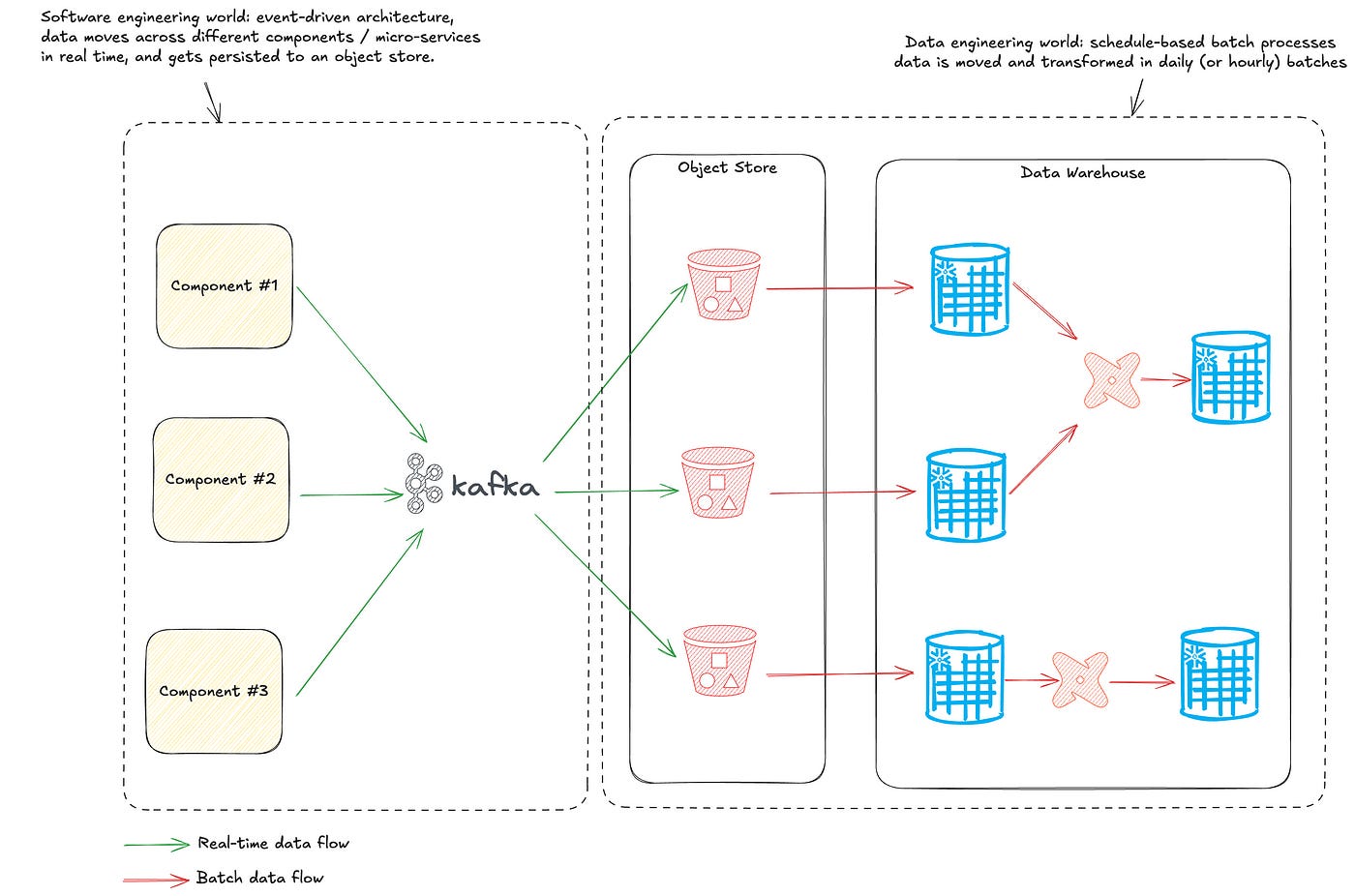
This architecture often resulted in data arriving at the data platform’s landing zone (typically an object store) in real-time but only being moved and transformed in batches, often on a daily schedule. Two arguments typically justified such architectures:
Ingesting and transforming data in real-time within the warehouse is more complex and expensive than batch processing.
The value generated by real-time use cases doesn’t justify the added cost and complexity.
However, these arguments are rapidly losing their validity. In my latest article on Towards Data Science, I discuss two major shifts that could make 2025 a tipping point for real-time analytics.
Out of the comfort zone: One layer too many
Tech companies have spent the last few years championing "efficiency" — often by streamlining their organizational structure and removing layers (i.e., middle management) to cut costs. The data world is experiencing its own efficiency push, with a focus on building business-value-driven data pipelines and minimizing the number of tools within the stack — but there's one area that should be the center of our efficiency discussions: data layers.
While most high-level architectures showcase the classic three-layer medallion approach (bronze/raw → silver/curated → gold/consumption-ready), many data teams in practice maintain far more “implicit” layers. Sometimes, data is even replicated multiple times within each layer due to ad-hoc use cases and lack of governance. So, as we strive to reduce costs and increase velocity, maybe it’s time to challenge our traditional layering approach?
A recent article by Adam Bellemare and Thomas Betts dives deep into this very question, arguing that it's time to rethink the bronze layer of the data platform by shifting it left. They propose several compelling options for building data products before the data even reaches the data platform's landing zone, rather than simply dumping everything into object storage and leaving data teams to untangle the complexity. If you're working on a data platform and looking to optimize costs or streamline your architecture, this article is a must-read.
If you enjoyed this issue of Data Espresso, feel free to recommend the newsletter to data folks in your entourage.
Your feedback is also very welcome, and I’d be happy to discuss one of this issue’s topics in detail and hear your thoughts on it.
Stay safe and caffeinated ☕