


Espresso #6: From data mess to data mesh, Spotify's data platform, and the post-MDS world
Make yourself an espresso and join me for a short break on a Monday afternoon ☕

Hello fellow data enthusiasts,
In this edition, we will talk about a path to successfully scaling your data platform, Spotify’s exceptional data culture, and the state of the data world after we declared the Modern Data Stack (MDS) dead. So without further ado, let’s talk data engineering while the espresso is still hot.
Navigating your data platform’s growing pains: a path from data mess to data mesh
When working on software components, developers can leverage a wide range of frameworks, design patterns, and principles to scale their products and seamlessly adjust their architecture to support new use cases and handle increasing usage and complexity. This allows software engineering teams to ensure optimized performance and reliability as their platform (and its value) grows in scale.
Data teams, however, are not so fortunate. While the initial months of a data platform’s lifecycle are often marked by the excitement of tackling complex technical challenges and the joy of delivering a first wave of data products, what often follows is a daunting spiral of mounting complexity, rising costs, and diminishing returns.
Unlike other problems that we need to navigate as data teams, our scalability struggles are inherently different from the ones faced by software teams. In the data world, these struggles come in the form of unavoidable technical complexity (like mixing a multitude of patterns to move and transform data across an ever-growing list of systems) and the data platform’s unique positioning within the company (since eventually every business unit gets connected to it either directly or indirectly).
So, in this post-MDS world, where data teams are thoroughly scrutinized over their spending and continuously asked to showcase their value, it is more important than ever to define standards and tenets for successfully scaling a data platform.
In my latest article, I offer five principles (complete with actionable strategies) to navigate the tricky state between being a new data team and building a large-scale data platform that generates substantial business value.
Fresh off the press: Spotify’s data platform
Among the big tech behemoths, some companies stand out from the rest when it comes to data - think Airbnb, Netflix, Uber, and Spotify. These companies play a key role in driving the data field forward by constantly rethinking their approaches to data and, more importantly, by being open about their data work (whether by open-sourcing the tools they build or sharing the learnings of their journey).
I’m personally a big fan of how the Spotify data teams approach their data projects, whether it’s to build the largest Dataflow job ever or to scale and democratize both analytics engineering and data visualization. Last week, Spotify published the first article in a new series that will discuss the different aspects of its data platform and data endeavors. I recommend following along the journey since it would definitely present many valuable learnings that can be applied when working on data projects.
Out of the comfort zone: The post-Modern-Data-Stack world
In the past few months, one of the hottest topics in the data world has been the death of the modern data stack. I believe that enough ink has been spilled on this topic, but I also want to reflect on the Modern Data Stack era and how it transformed the data field.
When I started my career in early 2017, the Hadoop ecosystem was all the rage. Companies were spending enormous resources on building data lakes that had a terrible return on investment and were very taxing to maintain. The problem wasn’t the data itself but the systems, which were simply too complex and, in most cases, barely working.
Fast forward to 2024. Last week, while reading dbt Labs’ annual state of analytics engineering report, I was pleasantly surprised by the following chart:
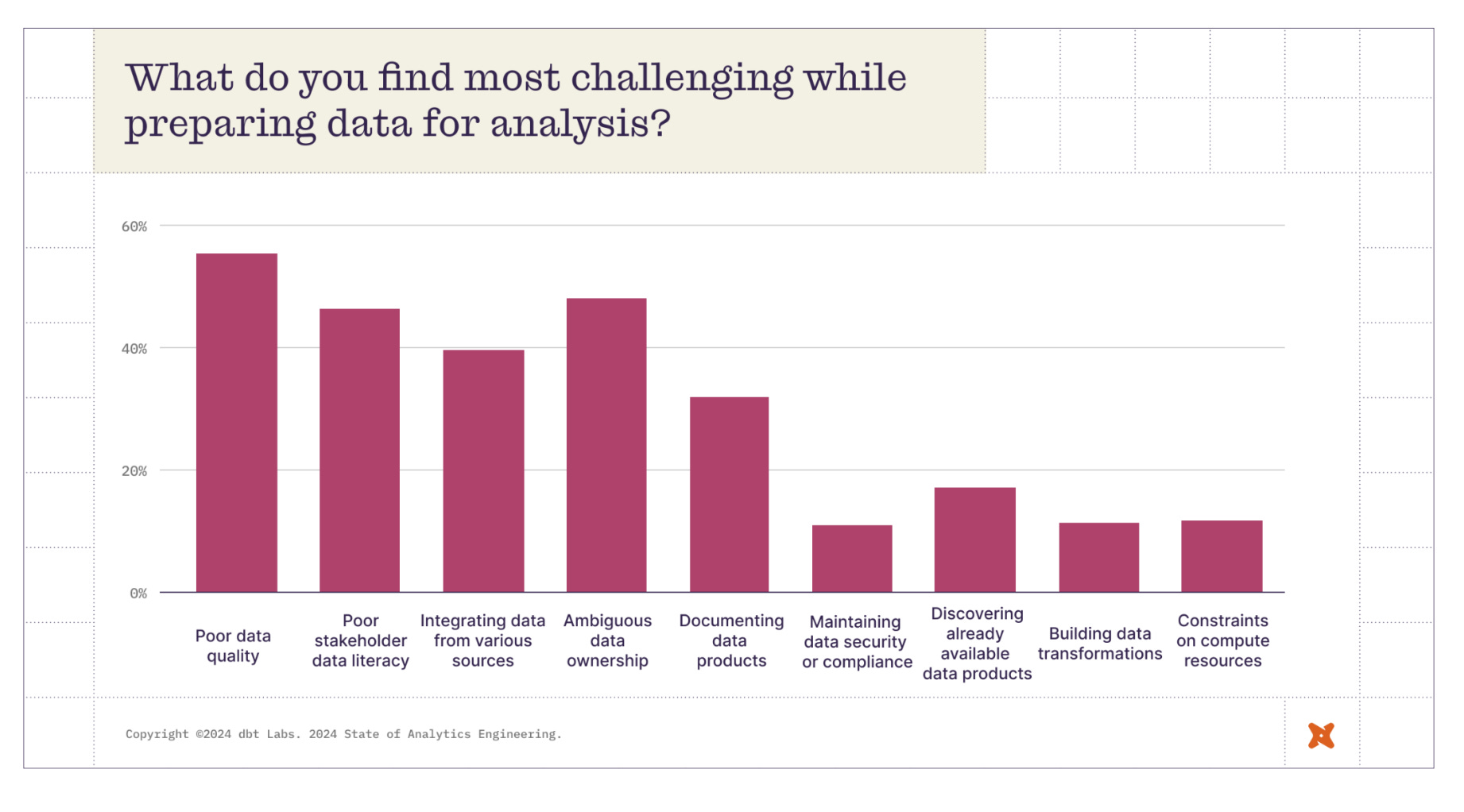
The takeaway is that we reached a state where the biggest two challenges that data teams face (poor data quality and ambiguous ownership) are related to people and processes and not to technical complexity or the data platform itself. This is, in a way, a direct acknowledgment of the modern data stack’s role in solving one of the Hadoop era’s biggest problems: today’s data platform just works. Gone are the days of messy configuration, navigating chaotic error logs across different systems, and spending endless engineering time on building and maintaining the platform.
The Modern Data Stack, for all its flaws, solved the data platform’s technical hurdles. Now it’s time to solve the business ones.
If you enjoyed this issue of Data Espresso, feel free to recommend the newsletter to people in your entourage.
Your feedback is also very welcome, and I’d be happy to discuss one of this issue’s topics in detail and hear your thoughts on it.
Stay safe and caffeinated ☕